


Summarize this content with artificial intelligence!

In this article, we discuss the brief history of natural language processing and the history of NLP.
Artificial Intelligence, for those not using it in daily life, seems like a concept exclusive to film productions or science fiction books.
However, the truth is that artificial intelligence is increasingly becoming a part of our lives and is a concept that is almost century-old.
As all these developments in artificial intelligence occur, a concept called NLP has emerged. The idea of machines understanding natural language? 😱 It may sound quite utopian.
In this article, we go back in time and read the brief but captivating history of natural language processing. Happy reading.
What is NLP?
Natural Language Processing (NLP), a subfield of artificial intelligence, is concerned with the interactions between computers and human (natural) languages, particularly interested in how computers should be programmed to process and analyze natural language data.
Natural language processing is a very important field for artificial intelligence because it can reduce human-machine interaction to a level that is very easy for humans to understand.
NLP appears in many applications such as the automatic summarization, classification, language translation, speech search and chatbots, among many other applications.
The history of natural language processing dates back to the 1950s. It has come a long way since then. However, there is still a longer road ahead because of the challenges it faces.
You might be wondering what these challenges could be. Let us explain; natural languages are quite complex in structure. Even in natural language, we all have different language models, but somehow we manage to communicate. Therefore, any model to be developed will be at least as complex. This is the part that makes language models difficult.
The History of Natural Language Processing
The Birth of Natural Language Processing (NLP) in the 1950s
The origins of natural language processing date back to the 1950s. In the 1950s, computer scientists began researching ways to teach machines to understand and generate human language.
In 1957, Noam Chomsky introduced the idea of generative grammar with his famous book Syntactic Structures. This idea provided researchers with an important foundation to understand how machine translation could work.
The potential of fully automatic and high-quality translation systems generated great excitement. However, it was quickly understood that these systems, which did not take into account the ambiguities of natural language, were ineffective at the time.
In 1966, the Automatic Language Processing Advisory Committee (ALPAC), established by the US government in 1964, published a report evaluating the progress of machine translation research. This report recommended the cessation of machine translation research. This recommendation significantly affected natural language processing and artificial intelligence research.
The ALPAC report we mentioned and the disappointments that came with the failure to meet expectations in artificial intelligence initiated the "winter" period in the history of artificial intelligence between 1966 and 1970, leading to a decline in artificial intelligence work during this period. ❄️

During this period, various language theories as well as some prototypes were developed. An outstanding example of this period is the “Eliza” program developed by Joseph Weizenbaum in 1966 was developed. We can consider it the first chatbot.
According to the claim, it was created to show how superficial human-computer communication was at the time. However, when placed on personal computers, people found it quite interesting. Like all other chatbots, its only task was to chat.
MIT professor Weizenbaum, who wanted to give Eliza a more interesting personality, wrote a code called DOCTOR in 1966 to work on Eliza.
This code turned Eliza into a psychiatrist. Eliza asked questions, tried to understand her patient, communicated with users through written text, and produced responses by analyzing the incoming expressions.
By today's standards, if we ask Eliza a few complex questions, we would quickly see that it fails. However, at that time, even though the answers were predetermined, people found Eliza quite interesting and felt like they were talking to a real person.
This situation highlighted the potential of human-computer interaction and demonstrated the need for further research in the field.
Rule-Based Systems in the 1960s-1970s
In the 1960s and 1970s, natural language processing (NLP) research focused on rule-based systems. These systems used predefined rules to analyze and process text.
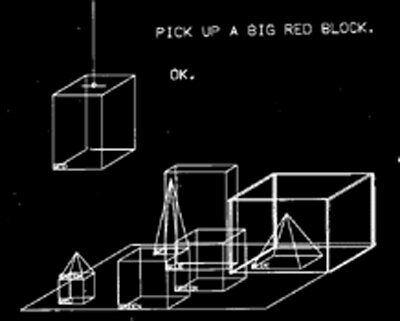
A prominent figure of this period was 1970, when Terry Winograd developed the “SHRDLU” program. When SHRDLU was first developed, it was hailed as a revolutionary artificial intelligence.
SHRDLU was a natural language understanding system that could manipulate blocks in a virtual world.
The world of SHRDLU was so simple that all the objects and places within it could perhaps be described with 50 words. These included names like "block" and "cone", verbs like "place" and "move", and adjectives like "big" and "blue".
Users could give commands like “Move the red block on top of the green block,” and SHRDLU could execute these tasks.
This system demonstrated the potential of NLP to understand and respond to complex instructions.
Statistical Approaches and Machine Learning in the 1980s-1990s
In the 1980s and 1990s, statistical approaches and machine learning techniques gained importance in natural language processing. A notable development during this period was the development of “Hidden Markov Models” (HMM) for speech recognition.
HMMs enabled computers to convert spoken language into written text and pioneered the development of speech-to-text systems. This advancement revolutionized areas such as text dictation and transcription.
Deep Learning and Neural Networks in the 2000s-2010s
In the 2000s, the use of neural networks became increasingly widespread. Additionally, during this period, words began to be defined as dense numerical vectors where words with similar meanings are represented by similar vectors, and these vectors were called word embeddings.
In 2006, the Google Translate service, one of the first successful natural language processing systems using statistical models for machine translation, was launched.
Another important development during this period was the development of word embedding models such as Word2Vec and GloVe.
Let us also touch upon what word embedding is.Word embedding is a technique in the field of natural language processing (NLP) that represents words as mathematical vectors.
These vectors aim to capture the meanings of words and the relationships between them in a continuous numerical space. Word embedding models represent words as low-dimensional dense vectors, and the geometric relationships between these vectors represent the contextual and semantic similarities of the words.
Word2Vec was developed by Tomas Mikolov and his team at Google in 2013 and has since become an industry standard.
Word2Vec represents the meanings and contextual relationships of words with mathematical vectors. For example, in the sentence “The cat chased the mouse”, “cat” and “mouse” often appear together, so their vectors are close to each other.
In 2014, a system consisting of two neural networks called Encoder-Decoder was proposed to generally describe problems that translate one sequence into another (for example, translating word sequences into word sequences in another language).
The Encoder-Decoder architecture became even more successful with attention mechanisms that enhanced the flow of information between the two modules.
This new system was so effective that in 2017, Google Translate abandoned its statistical model and began using a series of neural models. We will continue to explain this in the next section. 👇
2017
In 2017, Google introduced the Google Translate neural machine translation system using deep learning techniques. This system provided more fluent and accurate translations compared to traditional rule-based approaches.
Unlike its previous approach of translating phrase by phrase, it translated based on the entire sentence.
Google took a very successful step in this regard, and because it mimicked human thinking patterns, the quality of the translations produced was higher than that of normal machine translations.
This development made it easier to understand and communicate content in different languages.
Transformer Models and Large Language Models in the 2020s
In the last twenty years, natural language processing has undergone a transformation largely due to developments in machine learning and deep learning techniques.
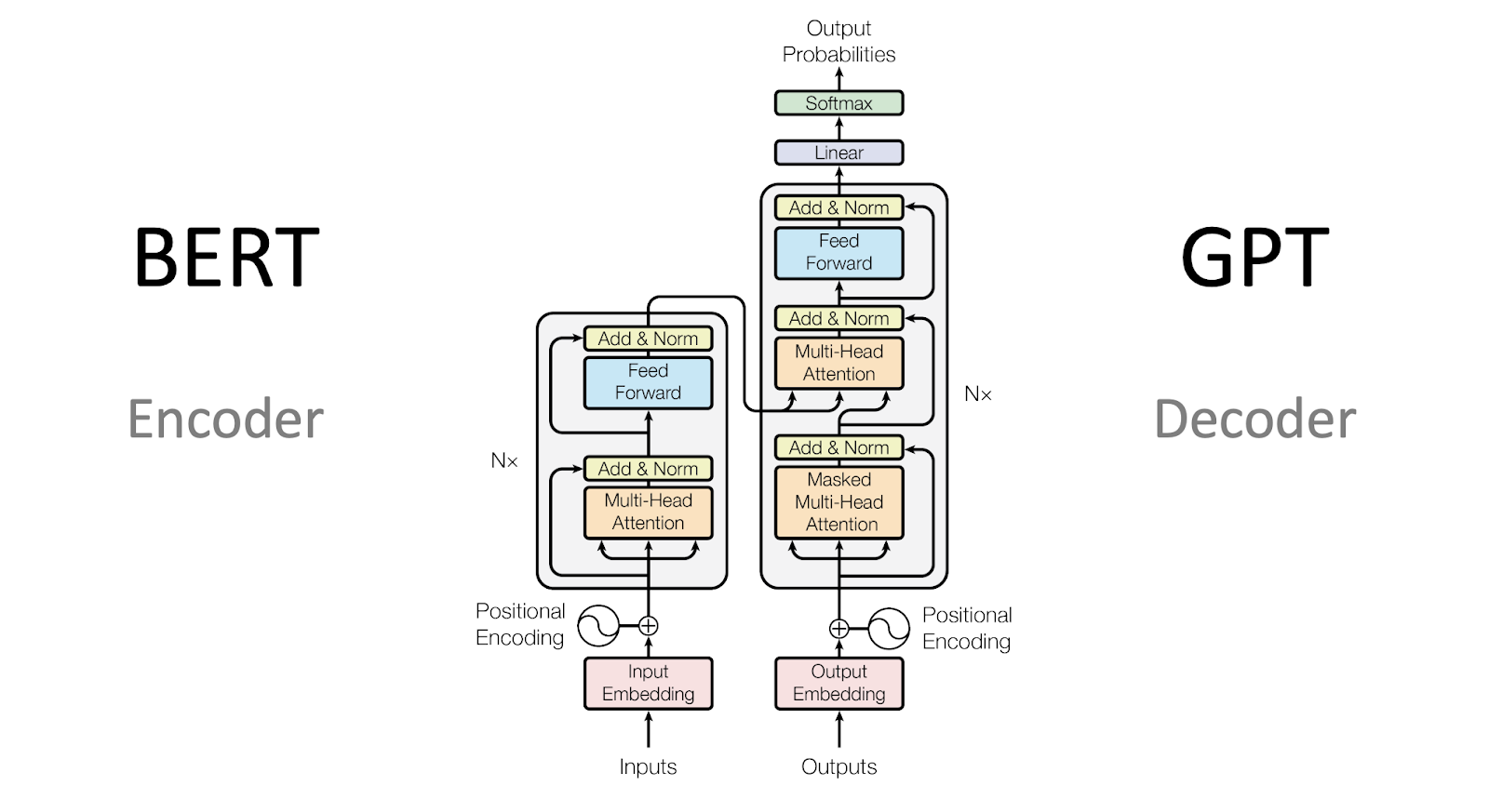
BERT and GPT, groundbreaking models, have kept us busy with tasks such as language translation, sentiment analysis, and automatic question answering.
These models can process and generate human-like text by capturing contextual dependencies within large amounts of training data.
GPT-3, released in 2020, demonstrated the ability to generate coherent and contextually appropriate text in various applications, from creative writing to customer support chatbots.
Looking to the Future
The history of natural language processing shows how the field has evolved from simple chatbots to sophisticated language models capable of understanding and generating human-like text.
From the first rule-based systems to today's advanced deep learning models, natural language processing has made incredible progress, but this journey is not yet complete. 🚶➡️
Despite its progress, natural language processing still faces significant challenges. Understanding context, irony, and nuanced language remains difficult for machines to grasp. Moreover, there is a need for systems that are not only accurate but also unbiased and ethical.
The future of natural language processing lies in overcoming these barriers and leveraging its synergy with other artificial intelligence technologies.
As natural language processing advances, we can expect new breakthroughs in areas like sentiment analysis, automatic summarization, and more realistic conversational chatbots.
Natural language processing has come a long way, and its future promises even more exciting possibilities for human-machine interactions.
Summarize this content with artificial intelligence!


