


Bu içeriği yapay zeka ile özetle!

Bu yazımızda doğal dil işlemenin kısa tarihini, NLP’nin tarihçesini anlatıyoruz.
Yapay zeka, günlük hayatta kullanmayanlar için film yapımlarına ya da bilim kurgu kitaplarına özgü bir kavram gibi görünüyor.
Ancak gerçek şu ki, yapay zeka giderek daha fazla hayatımızın içinde dahil olan ve neredeyse asırlık bir kavram.
Yapay zekadaki tüm bu gelişmeler yaşanırken bir de karşımıza NLP diye bir kavram çıktı. Makinelerin doğal dili anlaması fikri mi? 😱Kulağa oldukça ütopik gelebilir.
Bu yazımızda zamanda geriye doğru gidiyoruz ve doğal dil işlemenin kısa ama sürükleyici tarihini okuyoruz. Keyifli okumalar.
NLP Nedir ?
Doğal dil işleme (NLP), bilgisayarlar ile insan (doğal) dilleri arasındaki etkileşimlerle ilgilenen, özellikle bilgisayarların doğal dil verilerini işleyip analiz edecek şekilde nasıl programlanacağıyla ilgilenen yapay zekanın bir alt dalıdır.
Doğal dil işleme yapay zeka için çok önemli bir alan çünkü insan makine etkileşimini insanın çok kolay anlayabileceği bir seviyeye indirgeyebilir.
NLP, metinlerin otomatik olarak özetlenmesi, sınıflandırılması, dil çevirisi, sesli arama ve sohbet botları gibi çok sayıda uygulamada karşımıza çıkar.
Doğal dil işlemenin tarihi 1950’lere kadar dayanıyor. O zamandan bugüne kadar büyük bir yol kat etti. Ancak daha uzun bir yolu var çünkü karşısında zorluklar bulunuyor.
Ne olabilir ki bu zoruluklar diye düşünüyor olabilirsin. Şöyle açıklayalım; doğal diller yapıları gereği oldukça komplekstir. Doğal dilde bile hepimizin farklı dil modelleri var ancak bir şekilde iletişim kurmayı başarıyoruz. Dolayısıyla oluşturalacak bir model de en az bu kadar kompleks olacaktır. İşte dil modellerini de zorlayan kısım, bu kısımdır.
Doğal Dil İşlemenin Tarihçesi
1950’ler Doğal Dil İşlemenin (NLP) Doğuşu
Doğal dil işlemenin kökenleri için 1950’lerde kadar gidiyoruz. 1950’lerde bilgisayar bilimciler, makinelerin insan dilini anlamasını ve üretmesini öğretmenin yollarını araştırmaya başladılar.
1957 yılında Noam Chomsky’nin ünlü kitabı Syntactic Structures ile üretici dil bilgisi (generative grammar) fikri tanıtıldı. Bu fikir, makine çevirisinin nasıl çalışabileceğini anlamak için araştırmacılara önemli bir temel sağladı.
Tamamen otomatik ve yüksek kaliteli çeviri sistemlerinin potansiyeli büyük bir heyecan yarattı. Ancak, doğal dilin belirsizliklerini dikkate almayan bu sistemlerin, o dönemde etkili olmadığı kısa sürede anlaşıldı.
1966’da, ABD hükümeti tarafından 1964’te kurulan ALPAC (Automatic Language Processing Advisory Committee), makine çevirisi araştırmalarının ilerlemesini değerlendiren bir rapor yayımladı. Bu rapor, makine çevirisi araştırmalarının durdurulmasını tavsiye etti. Bu tavsiye, doğal dil işleme ve yapay zeka araştırmalarını geniş ölçüde etkiledi.
Bahsettiğimiz bu ALPAC raporu ve yapay zekadaki beklentilerin karşılanamamasıyla gelen hayal kırıklıkları 1966 ve 1970 arasında yapay zeka tarihindeki "kış" dönemini başlattı. Yani yapay zeka alanındaki çalışmalar bu dönemde oldukça azaldı. ❄️

Bu dönemde çeşitli dil teorilerinin yanı sıra bazı prototipler de geliştirildi. Bu dönemin öne çıkan bir örneği, 1966 yılında Joseph Weizenbaum tarafından geliştirilen “Eliza” programıdır. Onun için ilk chatbot diyebiliriz.
İddiaya göre o zamanlar insan-bilgisayar iletişiminin ne kadar yüzeysel olduğunu göstermek için yaratılmıştı. Ancak, kişisel bilgisayarlara konulduğunda, insanlar bunu oldukça ilgi çekici buldu. Diğer tüm sohbet robotları gibi tek görevi, sohbet etmekti.
Eliza’yı daha enteresan bir kişiliğe büründürmek isteyen MIT profesörü Weizenbaum, 1966 yılında Eliza’da çalışması için DOCTOR adında bir kod yazdı.
Bu kod Eliza’yı bir psikiyatriste dönüştürüyordu. Eliza sorular soruyor, hastasını anlamaya çalışıyor, kullanıcılarla yazılı metin üzerinden iletişim kuruyor ve gelen ifadeleri analiz ederek yanıtlar üretiyordu.
Günümüz standartlarına göre Eliza'ya birkaç karmaşık soru sorarsak çok çabuk başarısız olduğunu görürüz. Ancak o zamanlar, cevapları önceden belirlenmiş olmasına rağmen, insanlar Eliza’yı oldukça ilgi çekici buldu ve gerçek bir insanla konuşuyormuş gibi hissettiler.
Bu durum, insan-bilgisayar etkileşiminin potansiyelini gözler önüne serdi ve alanın daha fazla araştırılması gerekliliğini ortaya koydu.
1960’lar-1970’ler Kural Tabanlı Sistemler
1960’lar ve 1970’lerde doğal dil işleme (nlp) araştırmaları kural tabanlı sistemlere odaklandı. Bu sistemler, metni analiz etmek ve işlemek için önceden tanımlanmış kurallar kullandı.
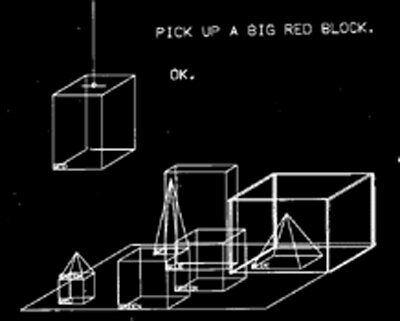
Bu dönemin öne çıkan ismi, 1970 yılında Terry Winograd tarafından geliştirilen “SHRDLU” programı oldu. SHRDLU ilk geliştirildiğinde devrim niteliğinde yapay zeka olarak adlandırıldı.
SHRDLU, sanal bir dünyada blokları manipüle edebilen bir doğal dil anlama sistemiydi.
SHRDLU'nun dünyası o kadar basitti ki, içindeki tüm nesneleri ve yerleri belki de 50 kelimeyle tanımlayabilirdi. Bunlar "blok" ve "koni" gibi isimler, " yerleştirmek" ve "taşımak" gibi fiiller ve "büyük" ve "mavi" gibi sıfatlardı.
Kullanıcılar, “Kırmızı bloğu yeşil bloğun üzerine taşı.” gibi komutlar verebiliyor ve SHRDLU bu görevleri yerine getirebiliyordu.
Bu sistem o yıllarda, NLP’nin karmaşık talimatları anlayıp yanıtlayabilme potansiyelini ortaya koydu.
1980’ler-1990’lar İstatistiksel Yaklaşımlar ve Makine Öğrenimi
1980’ler ve 1990’larda istatistiksel yaklaşımlar ve makine öğrenimi teknikleri doğal dil işlemede önem kazandı. Bu dönemde dikkat çeken bir gelişme, konuşma tanıma için “Gizli Markov Modelleri”nin (HMM) geliştirilmesiydi.
HMM’ler, bilgisayarların konuşulan dili yazılı metne dönüştürmesini sağladı ve konuşmadan metne sistemlerinin geliştirilmesine öncülük etti. Bu gelişme, metin dikte etme ve yazıya dökme gibi alanlarda devrim yarattı.
2000’ler-2010’lar Derin Öğrenme ve Sinir Ağları
2000’lerde, sinir ağlarının kullanımı giderek yaygınlaştı. Ayrıca bu dönemde, kelimeler, benzer anlamlara sahip olan kelimelerin benzer vektörlerle temsil edildiği yoğun sayısal vektörler olarak tanımlanmaya başlandı ve bu vektörler kelime yerleştirmeler (word embeddings) olarak adlandırıldı.
2006 yılında, makine çevirisi için istatistiksel modeller kullanan ilk başarılı doğal dil işleme sistemlerinden biri olan Google Translate hizmeti kullanıma sunuldu.
Bu dönemdeki diğer önemli gelişmelerden biri, Word2Vec ve GloVe gibi kelime yerleştirme modellerinin geliştirilmesiydi.
Burada kelime yerleştirmenin ne olduğuna da değinelim. Kelime yerleştirme (word embedding), doğal dil işleme (NLP) alanında kelimeleri matematiksel vektörler olarak temsil eden bir tekniktir.
Bu vektörler, kelimelerin anlamlarını ve aralarındaki ilişkileri sürekli bir sayısal uzayda yakalamayı amaçlar. Kelime yerleştirme modelleri, kelimeleri düşük boyutlu yoğun vektörler olarak ifade eder ve bu vektörler arasındaki geometrik ilişkiler, kelimelerin bağlamsal ve anlamsal benzerliklerini temsil eder.
Word2Vec, Tomas Mikolov ve ekibi tarafından 2013 yılında Google'da geliştirilmişti ve o zamandan beri endüstride bir standart haline geldi.
Word2Vec, kelimelerin anlamlarını ve bağlamsal ilişkilerini matematiksel vektörlerle temsil eder. Örneğin, “kedi fareyi kovaladı” cümlesinde “kedi” ve “fare” sıkça birlikte geçtiğinden, vektörleri birbirine yakın olur.
2014 yılında, bir sıralamayı başka bir sıralamaya çeviren sorunları (örneğin, kelime dizilerini başka bir dildeki kelime dizilerine çevirmek gibi) genel olarak tanımlayan Encoder-Decoder adlı iki sinir ağından oluşan bir sistem önerildi.
Encoder-Decoder mimarisi, iki modül arasındaki bilgi akışını artıran dikkat mekanizmaları ile daha da başarılı oldu.
Bu yeni sistem o kadar etkiliydi ki, 2017 yılında Google Translate, istatistiksel modelini bırakıp sinirsel bir dizi modeli kullanmaya başladı. Bunu da aşağıdaki bölümde anlatmaya devam ediyoruz. 👇
2017
Google, 2017 yılında derin öğrenme tekniklerini kullanarak Google Translate sinirsel makine çeviri sistemini tanıttı. Bu sistem, geleneksel kural tabanlı yaklaşımlara göre daha akıcı ve doğru çeviriler sağladı.
Eskiden yaptığının aksine öbek öbek çeviri yapmak yerine cümlenin tamamını baz alarak çeviri yaptı.
Google bu konuda çok başarılı bir adım atarak, insan düşünme biçimini taklit ettiği için çıkan çevirilerin kalitesi normal makine çevirisinden daha yüksek oldu.
Bu gelişme, farklı dillerdeki içeriği anlamayı ve iletişim kurmayı daha kolay hale getirdi.
2020’ler Transformer Modelleri ve Büyük Dil Modelleri
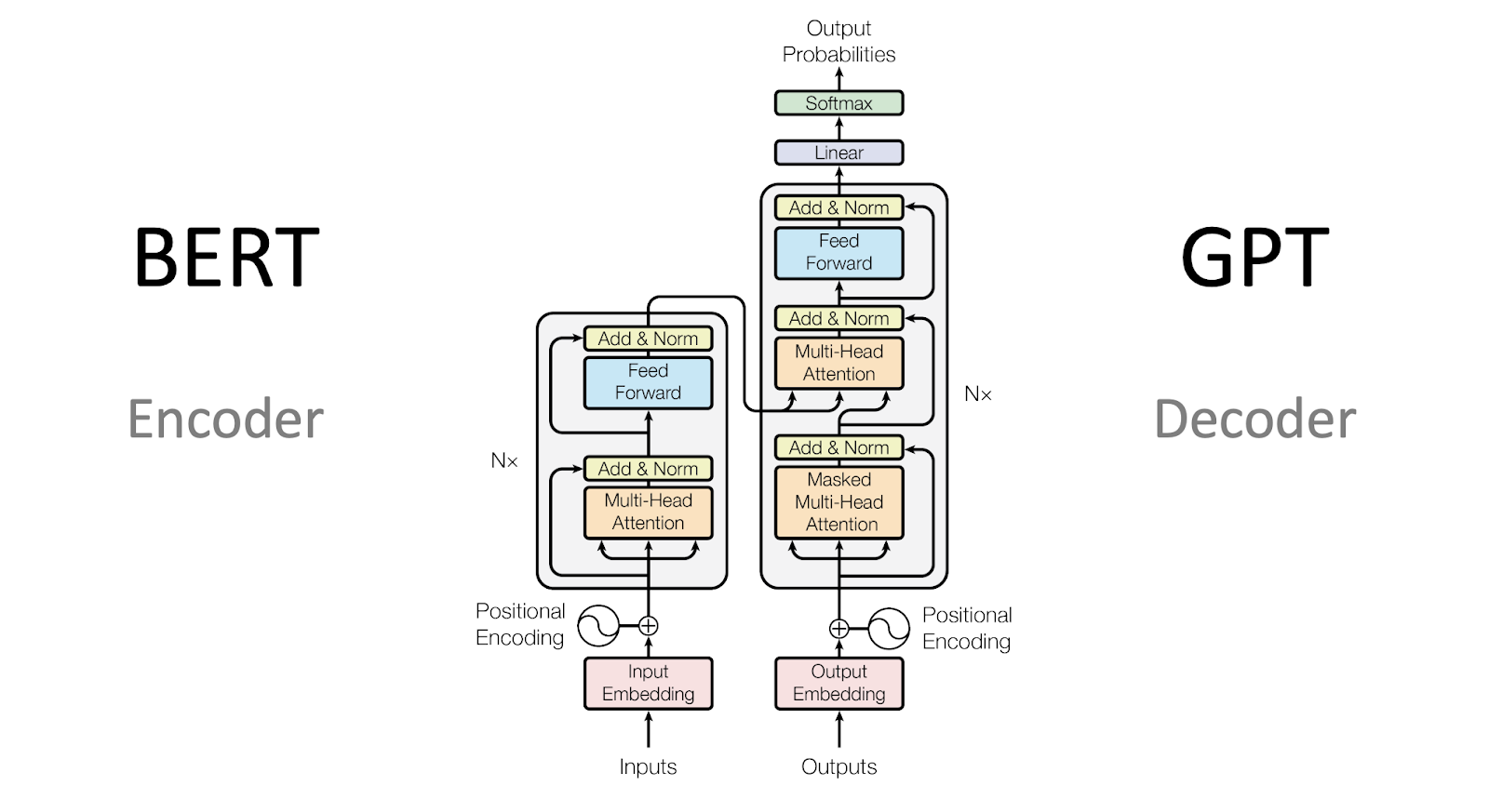
Son yirmi yılda doğal dil işleme, büyük ölçüde makine öğrenimi ve derin öğrenme tekniklerindeki gelişmelerle bir dönüşüm geçirdi.
BERT ve GPT gibi çığır açan modeller, dil çevirisi, duygu analizi ve otomatik soru cevaplama gibi görevlerde bizi bir hayli meşgul etti.
Bu modeller, büyük miktarda eğitim verisi içindeki bağlamsal bağımlılıkları yakalayarak insan benzeri metinler işleyip üretebiliyor.
2020 yılında yayımlanan GPT-3, yaratıcı yazıdan müşteri destek chatbot’larına kadar çeşitli uygulamalarda tutarlı ve bağlamsal olarak uygun metinler oluşturabilme yeteneğini gösterdi.
Geleceğe Bakış
Doğal dil işlemenin tarihi, alanın basit chatbot’lardan insan benzeri metinleri anlayabilen ve üretebilen sofistike dil modellerine nasıl evrildiğini gösteriyor.
İlk kural tabanlı sistemlerden günümüzün gelişmiş derin öğrenme modellerine kadar doğal dil işleme inanılmaz ilerlemeler kaydetti ancak bu yolculuk henüz bitmedi. 🚶➡️
Doğal dil işleme, ilerlemesine rağmen hala önemli zorluklarla karşı karşıya. Bağlamı, ironiyi ve nüanslı dili kavramak makineler için zor olmaya devam ediyor. Dahası, yalnızca doğru değil aynı zamanda tarafsız ve etik olan sistemlere de ihtiyaç var.
Doğal dil işlemenin geleceği, bu engellerin üstesinden gelmekte ve diğer yapay zeka teknolojileriyle sinerjisinde yatıyor.
Doğal dil işleme ilerledikçe, duygu analizi, otomatik özetleme ve daha gerçekçi sohbet chatbot’ları gibi yeni atılımlar bekleyebiliriz.
Doğal dil işleme uzun bir yol kat etti ve geleceği, insan-makine etkileşimleri için daha da heyecan verici olasılıkları vaat ediyor.
Bu içeriği yapay zeka ile özetle!





