


Bu içeriği yapay zeka ile özetle!

Günümüzde veriler, karar alma süreçlerinin merkezinde yer alıyor. Şirketler geçmişi anlamak, bugünü analiz etmek ve geleceği öngörmek için veriye her zamankinden daha fazla ihtiyaç duyuyor.
İşte tam da burada veri analizi, ham verileri anlamlı içgörülere dönüştüren en önemli becerilerden biri olarak karşımıza çıkıyor.
Veri analizi, uygulanabilir içgörüler ortaya çıkarmak için verilerin toplanması, standartlaştırılması, dönüştürülmesi ve yorumlanmasını içerir.
Ayrıca, veri analizi veri biliminin bir parçasıdır ve bu nedenle birçok yapay zeka ve makine öğrenimi iş akışının temelini oluşturur.
Python ise veri analizi dünyasında en çok tercih edilen programlama dillerinden biri. Programlama dillerinin popülerliğini ölçen TIOBE Endeksi'ne göre Python, dünyanın en popüler programlama dilidir.
Öğrenmesi görece kolay, okunabilir bir syntax’a sahip ve güçlü kütüphanelerle desteklenen bir dil... Hem teknik geçmişi olanlar hem de veri analizine yeni başlayanlar için idealdir.
Peki ama Python veri dünyasında ne işe yarar? 👀

Python, Veri Analizinde Nasıl Kullanılır?
Diyelim ki iki farklı mağaza için haftalık olarak sipariş verilerin kıyafetlerin listesini içeren bir sürü ayrı Excel dosyası alıyorsun ve bu verileri daha ileri analizler için tek bir tabloda birleştirmen gerekiyor. Bunu tabii ki Excel kullanarak yapabilirsin ya da bunun yerine aynı işi yapan tek satırlık bir Python kodu çalıştırabilirsin.
Peki Python neden Excel’den güçlü?
- Büyük veri setleriyle çok daha hızlı çalışır
- Tekrarlanabilir ve otomatik analizler yapılabilir
- Hatalar manuel değil, kodla kontrol edilir
- Aynı analiz her gün tek tuşla çalıştırılabilir
Python, verileri temizlemeye, verileri görselleştirmeye ya da belirli görevleri ve süreçleri otomatikleştirmeye yardımcı olur.
Python ile veri analizi yapmak, yalnızca tablolarla çalışmak anlamına gelmez. Aynı zamanda tekrar eden işleri otomatikleştirmeyi, büyük veri setlerini verimli şekilde işlemeyi ve analiz sonuçlarını net bir şekilde sunmayı da kapsar.
Veri Toplama
'Nasıl' kısmına geçmeden önce, 'nereden' olduğunu anlamak önemlidir.
Veri toplama ve depolama becerisi, her veri bilimcinin araç setinin önemli bir parçasıdır. Veri kaynakları aslında verilerimizin nereden geldiğini ifade eder.
Peki Python’da veri nasıl toplanır?
Bunun için birkaç yöntem mevcut. Şimdi onlara bakalım.
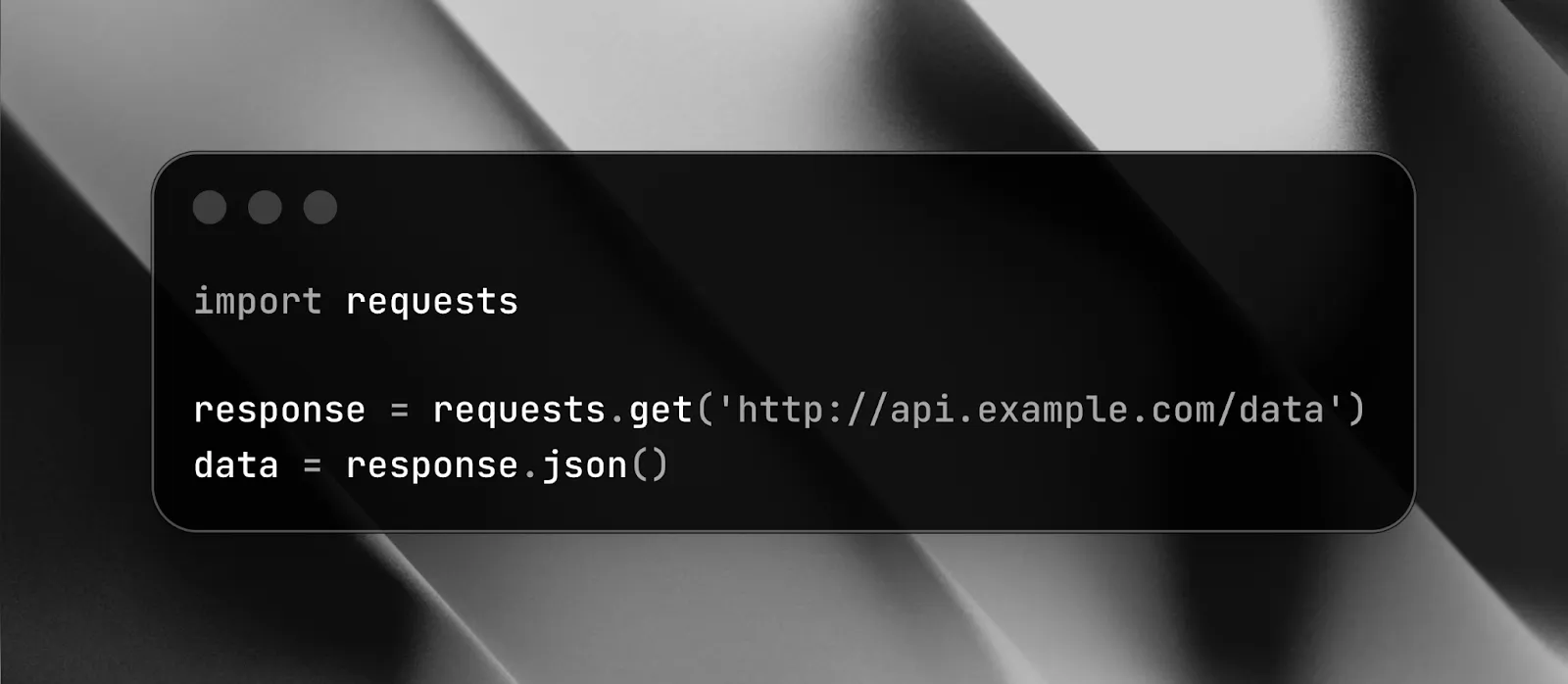
1. Açık API’ler: requests Kullanımı
Açık API’ler internet üzerinden veriye erişmenin en kolay yollarından biridir. Python’daki requests kütüphanesi, HTTP istekleri yapmayı oldukça kolaylaştırır.
Örneğin, aşağıdaki kod, belirtilen adresteki veriyi çeker ve JSON formatında Python’a aktarır. Bundan sonra veriyi analiz veya görselleştirme için kullanabilirsin.
2. Web Scraping: BeautifulSoup ve Scrapy
Bazen veriler bir web sitesinde yer alır ve API sunulmamış olabilir. Bu durumda web scraping yöntemleri kullanılır.
- BeautifulSoup: Beautiful Soup, HTML ve XML belgelerini ayrıştırmak için kullanılan bir Python kütüphanesidir. Web sitelerinin HTML veya XML kodundan veri çıkarmak için web kazıma projelerinde yaygın olarak kullanılır.
- Scrapy: Scrapy, Python ile yazılmış ücretsiz ve açık kaynaklı bir web tarama framework’üdür. Web sitelerinden veri çıkarır ve CSV gibi yapılandırılmış bir biçimde kaydeder. Scrapy, büyük ölçekli veri çıkarma işleri için kullanışlıdır ve hızlı ve verimli olacak şekilde tasarlanmıştır.
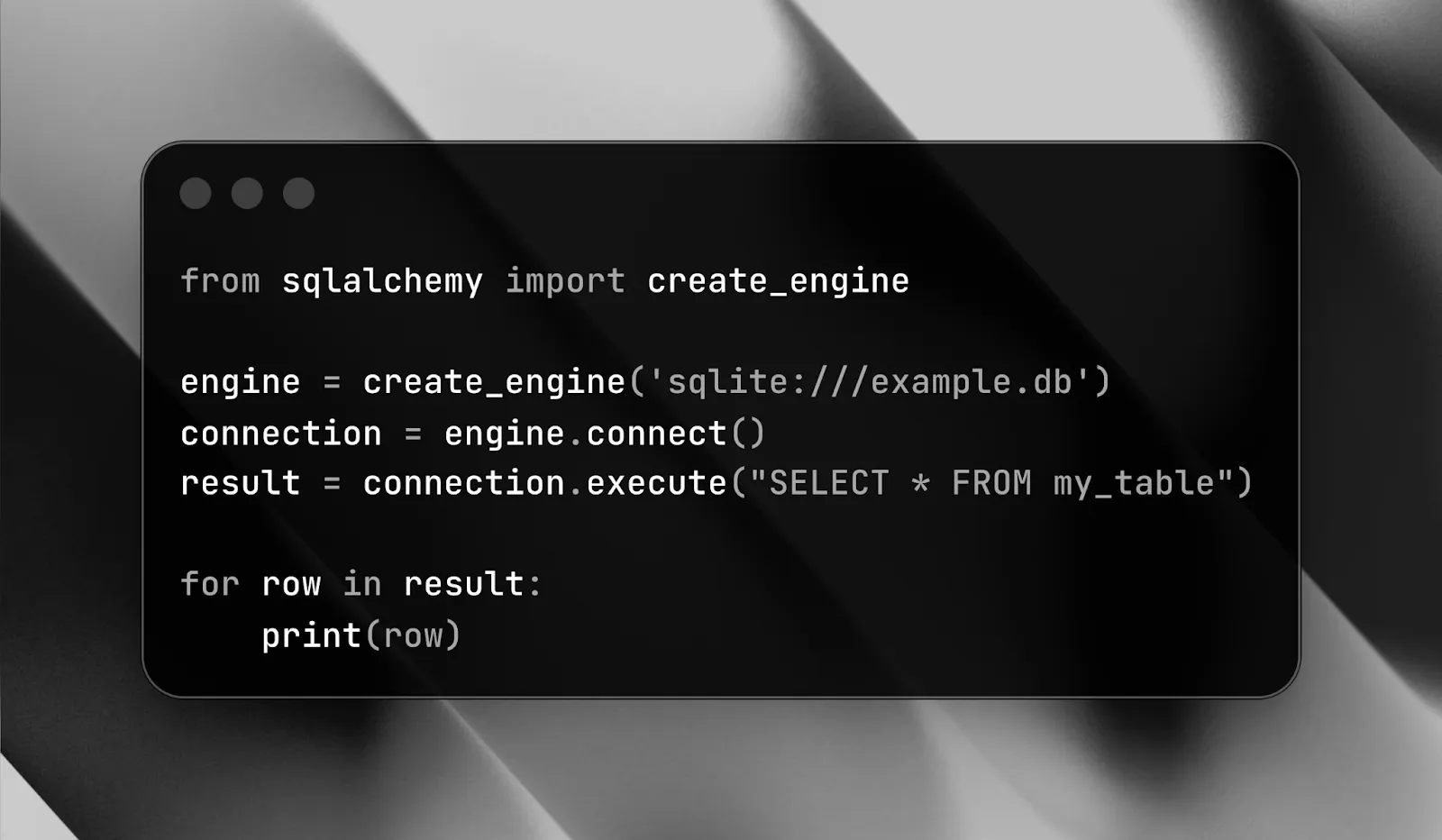
3. Veri tabanlarından Veri Çekmek: SQLAlchemy
Veri çoğu zaman CSV veya Excel dosyalarının dışında veri tabanlarında saklanır. Python’da SQLAlchemy kütüphanesi, veri tabanı ile çalışmayı kolaylaştırır ve SQL sorgularını Python ile entegre etmeyi sağlar.
Veri İşleme
Verilerini kalitesi, analizin doğruluğunu ve model performansını doğrudan etkiler. Neden? Çünkü ham veriler genellikle tutarsızlıklar, hatalar ve sonuçları bozabilecek ve hatalı içgörülere yol açabilecek alakasız bilgiler içerir. İşte veri işleme, bu sorunu hafifletmenin bir yoludur.
Veri işleme, ham verileri temiz, yapılandırılmış bir biçime dönüştürme işlemidir.
Veri işleme her biri veri kalitesi, yapısı ve alaka düzeyiyle ilgili çeşitli adımları içerir. Şimdi bu adımlara bakacağız ancak detayları ayrı bir blog yazısının konusu.
- Veri Temizleme: Ham verideki eksik, hatalı veya tutarsız kayıtları tespit edip düzeltmek.
- Veri Dönüştürme: Verileri analiz ve modelleme için uygun formatlara dönüştürmek.
- Veri Normalizasyonu / Standardizasyonu: Farklı ölçeklerdeki verileri karşılaştırılabilir hale getirmek.
- Eksik Veri Yönetimi: Eksik değerleri silmek, doldurmak veya uygun şekilde işlemek.
- Veri Birleştirme: Farklı veri kaynaklarını tek bir yapı altında birleştirmek.
- Özellik Seçimi: Analiz için en anlamlı ve etkili değişkenleri belirlemek.
- Veri Özetleme ve İnceleme: Verinin genel yapısını ve temel istatistiklerini anlam.
Veri işlemeyi tamamen Python kodu kullanarak gerçekleştirebilirsin ancak çeşitli görevleri yerine getirmek ve genel süreci daha verimli hale getirmek için güçlü araçlar da mevcut.
📚 Kütüphaneleri kullanabilirsin;
- Pandas:
Bunlardan bir tanesi Pandas kütüphanesi.
Python kütüphanelerinden Pandas, büyük veri tablolarıyla etkili bir şekilde çalışmak için bir veri yapısı sunar.
Eksik verileri işleme, veri kümelerini birleştirme, verileri filtreleme ve yeniden şekillendirme gibi işlemleri destekler.
Genel olarak, iş verimliliğini artırmak için çeşitli veri analizi işlevlerini gerçekleştirmemize yardımcı olur.
- Scikit-learn:
Makine öğrenimi görevlerinde yaygın olarak kullanılır, ancak ölçeklendirme, kodlama ve veri dönüştürme gibi çok sayıda ön işleme aracı da sunar. Ön işleme modülü, kategorik verileri işleme, sayısal verileri ölçeklendirme, özellik çıkarma ve daha fazlası için araçlar içerir.
☁️ Bulut platformları kullanabilirsin;
Şirket içi sistemler büyük veri kümelerini etkili bir şekilde işleyemeyebilir. Bu gibi durumlarda bulut platformları, büyük miktarda veriyi işlemeyi sağlayan ölçeklenebilir ve verimli çözümler sunar.
Öne çıkan iki bulut platformunu şöyle listeledik;
- AWS Glue: Amazon’un sunduğu bir bulut hizmetidir ve verileri otomatik olarak temizleyip analiz için hazır hale getirir.
- Azure Data Factory: Microsoft’un bulut hizmeti olarak, verileri farklı kaynaklardan toplayıp dönüştürmeyi ve taşımayı kolaylaştırır.
🛞Otomasyon araçları da mevut;
Veri ön işleme adımlarının tekrarlayan kısımlarını otomatikleştirmek, özellikle makine öğrenimi modelleri ve büyük veri kümeleriyle çalışırken zamandan tasarruf sağlayabilir ve hataları azaltabilir.
- AutoML platformları: Otomatik Makine Öğrenimi (AutoML) platformları, veri dönüştürme, özellik seçimi ve model seçimi gibi makine öğrenimi adımlarını minimum kullanıcı müdahalesiyle otomatikleştirir. Bunun örnekleri arasında Google AutoML, Azure AutoML ve H2O.ai bulunur.
- Scikit-learn Pipeline: Scikit-learn’ün Pipeline sınıfı, birden fazla veri ön işleme adımını tek bir iş akışında birleştirir ve bu sayede işlemlerin tutarlı ve tekrarlanabilir şekilde uygulanmasını sağlar.
Veri Görselleştirme
Veri analistlerinin anlamlı içgörüleri anlaşılabilir bir formatta sunmaları gerekir. Matplotlib gibi Python kütüphaneleri, veri analistlerinin sayıları grafikler, histogramlar haline dönüştürmesine olanak tanır.
İstatistiksel Analiz
İstatistiksel işlemlere odaklanan kütüphaneler, değişkenler arasındaki ilişkileri değerlendirmek için idealdir. Örneğin, gözlemlenen bir korelasyonun anlamlı bir eğilimi gösterip göstermediğini veya sadece tesadüfi olup olmadığını belirlemeye yardımcı olabilirler.
Makine Öğrenimi ve Tahmine Dayalı Modelleme
Makine öğrenimi için tasarlanmış kütüphaneler, tahmine dayalı modeller oluşturma sürecini kolaylaştırır. Örneğin, bir sağlık hizmeti sağlayıcısı, yaş, tıbbi geçmiş ve mevcut semptomlar gibi çeşitli faktörlere dayanarak hastanın yeniden hastaneye yatırılma olasılığını tahmin eden istatistiksel bir model oluşturmak için bu araçlardan yararlanabilir. Bu tür modeller, özellikle gerçek zamanlı veri ile beslendiğinde daha doğru sonuçlar üretir. Bu da 5G teknolojisi gibi hızlı veri iletim altyapılarının önemini artırır.
Python’ı Veri Analizinde Kullanmak için Nasıl Öğrenebilirim?
İlk olarak veri analizi için Python’a odaklanan bir yol haritası oluşturmalısın. Burada özellikle veri analizine vurgu yaptık çünkü amacımız Python’ı veri analizi için kullanmak. Aksi halde Python’daki diğer konuları veri analizi için öğrenmek zaman olabilir. Bu yüzden odağını daraltmalısın.
Önce Python’ın temellerini çok iyi öğren, sonra NumPy, Pandas, Matplotlib ve Seaborn gibi temel kütüphanelerde ustalaş.
Temeller derken aslında şunları kastediyoruz;
- Veri tipleri: int, float, string, boolean gibi temel veri tiplerini ve bunların ne zaman, nasıl kullanıldığını bilmek
- Koleksiyon yapıları: Listeler, demetler (tuple), kümeler (set) ve sözlükler (dictionary) arasındaki farkları ve kullanım senaryolarını anlamak
- Mutable ve immutable nesneler: Hangi nesnelerin değiştirilebilir olduğunu ve bunun kod davranışını nasıl etkilediğini kavramak
- Koşullu ifadeler: if, elif, else yapılarıyla mantıksal karar mekanizmaları kurabilmek
- Döngüler: for ve while döngülerini kullanarak tekrarlayan işlemleri verimli şekilde gerçekleştirebilmek
- Fonksiyonlar: Kendi fonksiyonlarını yazabilmek, parametre ve dönüş değerlerini doğru şekilde kullanmak
- Lambda fonksiyonları: Kısa ve tek satırlık işlemler için lambda ifadelerinden faydalanmak
- Hata yönetimi: try, except, finally bloklarıyla hataları yakalamayı ve yönetmeyi öğrenmek
- Temel yerleşik fonksiyonlar: len(), range(), enumerate(), zip() gibi sık kullanılan built-in fonksiyonları etkin kullanmak
- Dosya işlemleri: CSV ve TXT gibi dosyalardan veri okuma ve yazma işlemlerini gerçekleştirebilmek
- Nesne yönelimli programlamaya giriş: Sınıflar (class), nesneler (object), örnekler (instance) ve temel mantığı hakkında fikir sahibi olmak
Temelleri öğrenirken kodları mümkün olduğunca kendin yazmaya çalış. Evet, kopyalayıp yapıştırmak ya da AI araçlarına kod yazdırmak artık çok kolay ama kodu gerçekten sen yazdığında çok daha kalıcı olacak.
Temel bilgileri sağlamlaştırdıktan sonra sırada temel kütüphaneler var.
Veri analistlerinin kullandığı başlıca Python kütüphaneleri pandas, NumPy, Matplotlib, Seaborn, Plotly, SciPy ve Scikit-learn'dür. Diğer popüler Pandas araçları arasında Anaconda ve Jupyter Notebook bulunur.
Veri Analizi için Python Kütüphaneleri şöyle 👇
1. NumPy

İlk olarak NumPy’den bahsedelim.
NumPy (Numerical Python'ın kısaltması), Python'da sayısal hesaplama için kullanılan temel bir kütüphanedir.
Vektörler ve matrislerle çalışmak üzere tasarlanmış, büyük veri hacimlerinin sayısal hesaplamalarını ve analizini kolaylaştıran bir Python kütüphanesidir.
Özellikle veri bilimi, mühendislik ve matematik gibi alanlarda bilimsel programlamada yaygın olarak kullanılmaktadır.
NumPy, veri analizi için çeşitli önemli avantajlar sunmaktadır:
- Bellek tüketimini azaltır.
- İşlem hızını artırır.
- Her seviyeden Python kullanıcısı için erişilebilirdir.
2. Pandas

Pandas, veri işleme ve analizini basitleştirmek için tasarlanmış, Python programlama dili için açık kaynaklı bir kütüphanedir.
Aylık 100 milyondan fazla indirme sayısıyla, veri işleme ve keşifsel veri analizi için fiili standart pakettir.
Pandas, Python'da tablo halindeki veriler için bir veri işleme paketidir. Yani, satır ve sütunlar şeklinde olan veriler, diğer adıyla DataFrame'ler.
Pandas'ın işlevselliği, satırları sıralama ve alt kümeler alma gibi veri dönüşümlerinden, ortalama gibi özet istatistikleri hesaplamaya, DataFrame'leri yeniden şekillendirmeye ve DataFrame'leri birleştirmeye kadar uzanır.
Pandas ile şunlar yapılabilir:
- Veri tabanlarından, elektronik tablolardan ve CSV dosyalarından veri kümelerini içe aktarır
- Eksik, hatalı veya tutarsız verileri tespit eder ve temizler
- Veri kümelerini analiz için uygun bir yapıya dönüştürerek düzenler
- Özet istatistikler (ortalama, dağılım, korelasyon vb.) hesaplayarak veriyi anlamlandırır
- Veri kümelerini görselleştirerek eğilimleri ve önemli ilişkileri ortaya çıkarır
Şimdi sırada Python’da görselleştirmeler var 📊
1. Matplotlib
Veri görselleştirme, karmaşık veri kümelerini anlamaya yardımcı olur. İşte burada karşımızda çıkan kütüphanelerden biri Matplotlib.
Matplotlib, iki boyutlu grafikler ve diğer veri görselleştirmeleri ve modelleri oluşturmak için yaygın olarak kullanılan bir Python kütüphanesidir.
Çok sayıda grafik türünü ve özelleştirme seçeneğini destekleyerek bilimsel araştırma, veri analizi ve görsel iletişim için değerli hale gelen esnek bir kütüphanedir.
- Çizgi grafikleri
- dağılım grafikleri
- Histogramlar
- çubuk grafikler
- pasta grafikler
- kutu grafikleri
- 3 boyutlu çizim desteği sunar.
2. Diğer Popüler Python Veri Görselleştirme Kütüphaneleri:
- Seaborn – Matplotlib üzerine kuruludur. İstatistiksel görselleştirmeleri ve estetik grafik tasarımlarını kolaylaştırır.
- Plotly – Etkileşimli ve dinamik grafikler oluşturmanı sağlar. Web uygulamalarıyla kolayca entegre edilebilir.
- Altair – Basit ve deklaratif bir şekilde görselleştirme yapmayı sağlar. Özellikle veri analizi ve raporlama için uygundur.
- Bokeh – Büyük veri setleriyle etkileşimli görselleştirmeler yapmayı kolaylaştırır. Web tabanlı görselleştirme için ideal.
Bundan Sonra Ne Öğrenmeliyim?
Bu noktaya kadar Python’ın veri analizinde neden bu kadar güçlü bir araç olduğunu ve hangi temel kütüphanelerin kullanıldığını gördük.
Python ile veri analizine başlarken bazı yaygın hatalar da mevcut ve bu hatalar öğrenme sürecini gereksiz yere zorlaştırabilir.
Bu hataların farkında olursan öğrenme sürecin çok daha kolay hale gelebilir. Bu hataları da hızlıca özetlemek istedik;
- Temelleri atlayıp doğrudan kütüphanelere geçmek
Değişkenler, döngüler ve fonksiyonlar tam oturmadan Pandas veya NumPy öğrenmeye çalışmak, kodu ezberlemeye ve çabuk unutmaya yol açar. - Kodu kopyalayıp yapıştırmak
Kodun çalışması öğrenildiği anlamına gelmez. Kodu satır satır anlayarak ve mümkün olduğunca kendin yazarak ilerlemek kalıcılığı ciddi şekilde artırır. - Veriyi temizlemeden analiz yapmaya çalışmak
Eksik, hatalı veya tutarsız verilerle yapılan analizler yanıltıcı sonuçlar üretir. Veri temizleme, analiz sürecinin olmazsa olmazıdır. - Her şeyi aynı anda öğrenmeye çalışmak
Python çok geniş bir ekosisteme sahiptir. Her konuyu aynı anda öğrenmeye çalışmak yerine, veri analizine gerçekten katkı sağlayan başlıklara odaklanmak gerekir. - Pratik yapmamak
Sadece video izlemek veya yazı okumak yeterli değildir. Gerçek veri setleriyle düzenli pratik yapılmadığında bilgiler hızla unutulur.
Bundan sonraki en önemli adım bizce öğrendiklerini gerçek veriler üzerinde uygulamak. 📍
Küçük ama gerçekçi veri setleriyle çalışarak veri temizleme, analiz ve görselleştirme pratikleri yapmaya odaklanabilirsin. Açık veri kaynaklarından indirilen basit CSV dosyaları bile bu süreç için fazlasıyla yeterli.
Temel kütüphanelere hakim olduktan sonra keşifsel veri analizi (EDA), zaman serisi analizi ve temel istatistik konularına geçebilirsin.
Ardından Scikit-learn gibi kütüphanelerle makine öğrenimine giriş yapmak, veri analizini bir adım öteye taşımanı sağlar.
Bu sürede veri analizi alanında çalışan profesyonellerin hikayelerini ücretsiz bir şekilde dinlemek için meet-up’larımıza göz atabilirsin.
Bu içeriği yapay zeka ile özetle!





